概览
Azkanban是LinkedIn公司开发的、用于解决Hadoop任务依赖问题的一套实现方案。我们( LinkedIn )有许多需要按顺序运行的任务,包括 ETL1任务和数据分析产品。
Azkaban 包含3个关键组件:
- 关系数据库( MySQL )
- AzkabanWebServer
- AzkabanExecutorServer
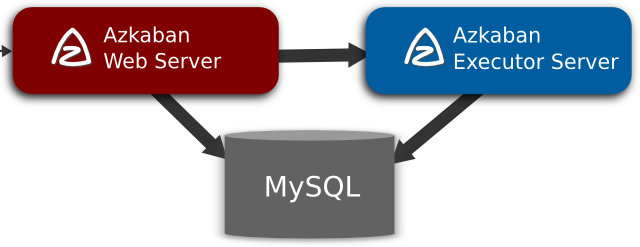
关系数据库( MySQL )
AzkabanWebServer如何使用DB?
web server 基于以下原因使用DB:
- 工程( Project )管理 - 管理工程,工程的权限以及上传文件
- 执行中的工作流( Flow )的状态 - 保存执行中的工作流和运行这些工作流的Executor的追踪信息
- 前置的工作流/任务( Job ) - 查询之前的任务和工作流执行情况,以及查看它们的日志
- 调度器 ( Scheduler ) - 保存调度任务的状态
- SLA - 保存所有的 sla 规则
AzkabanExecutorServer如何使用DB?
executor server 基于以下原因使用DB:
访问工程 - 从DB中获取工程文件
执行工作流/任务 - 为执行中的工作流获取和更新数据
日志 - 存储任务和工作流的输出日志到DB
Interflow 依赖 - 如果一个工作流运行在不同的执行器上,它需要从DB获取状态信息
MySQL作为一个被广泛使用的DB,没有理由不选择它。我们也期待其他DB的兼容实现,尽管在查询历史运行任务的搜索上,关系数据存储可以满足需求。
AzkabanWebServer
AzkabanWebServer 是所有 Azkaban 组件中的主要管理模块。它负责工程管理、用户认证、任务调度和监控。它同时也承担 web 用户界面的功能。
使用 Azkaban 很简单。Azkaban 使用后缀名为 job 的key-velue 配置文件( *.job )来配置一个工作流(work flow)中所包含的各个独立的任务,其中的 _dependencies_ 字段用来描述任务的依赖关系。将这些 job 文件和相关代码打包在一个zip包中,然后使用 Azkaban 的 web 界面或 curl 命令上传到 web 服务器(即 AzkabanWebServer )上。
AzkabanExecutorServer
之前版本的 Azkaban 把 AzkabanWebServer 和 AzkabanExecutorServer 功能放在一个单独的服务器中。目前 Executor 已经拆分到独立的服务器中。官于拆分服务有下面几个原因:我们可以迅速对执行者的数量进行水平扩展、对某个在操作中失败的 Executor 进行回退;同时我们也可以在对用户影响最小的情况下对 Azkaban 进行升级回滚;随着 Azkaban 使用量的增加,我们发现升级变得越来越困难,因为一天中的所有时间段都是“使用高峰期”。
附录
1. ETL:“Extract, Transform, Load” 的简称,指代从数据源提取数据、加工、写入结果数据集等三个处理过程;将这三个过程合并到一个工具中(如程序代码、shell脚本等)进行处理,则这个工具就承担了ETL的作用,运行这个工具即可称之为“运行 ETL 任务” ↩
参考:http://searchdatamanagement.techtarget.com/definition/extract-transform-load